前情提要:以下內容全為個人主觀意見,紀錄近期在開發導入 AI 輔助的實戰反思。
要怎麼用AI 寫出穩定度高的程式碼?
這一兩年有很多新名詞跑出來,像是 Prompt Engineering、Harness Engineering、Context Engineering 等等。
有人研究指出,即使是使用較低階的模型,只要事先定義好嚴謹的規格,成效甚至能逼近頂級模型。在我近期的實作體驗中也有很深的共鳴:把各種規格訂清楚,AI 就越有機會乖乖照著你的規則和想法走。
為什麼「減法」才是目前最難的?
要訂出能讓 AI 產出預期結果的規則,其實非常困難。每個人的開發習慣、提問方式以及需要的流程都不一樣。
這同時也是工程師在建立個人 Workflow 時的優點與致命傷——我們太容易「過度設計」了。 我們常常想要面面俱到,結果把整個流程搞得極度肥大,不僅白白浪費了 Token,還把操作空間限縮得太死。這反而會導致 AI 的產出更容易偏離預期。
在這個資訊大爆炸的時代,每隔幾天 GitHub 上就會跳出某個破千 Star 的超神 Skill 或 Plugin,告訴你寫 Code 可以多方便。但我認為,剛開始接觸 AI Coding,第一步就是「什麼都不要裝,直接開始寫」。 網路上花招太多了,只有實際用過,才會知道自己真正的痛點在哪。缺什麼再去寫對應的 Skill,或者只挑選那些高 Star 專案中最符合需求的幾支 Plugin 來用就好。
控制 AI 的爆炸半徑
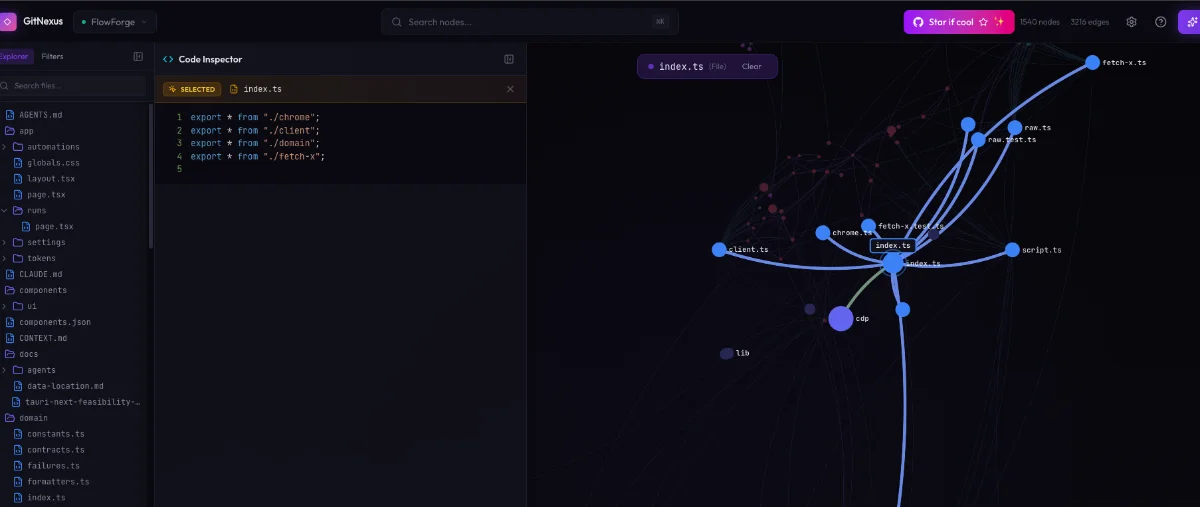
AI 寫 Code 還有一個大坑:如果沒有給它明確的限制,你叫它改 A,它很可能會順手把 B 也改壞了。這種情況非常容易發生。 我目前是引入 GitNexus 來解決這個問題。它的優點是能直接掃出整個專案的關聯圖,讓我更容易控制每個 Issue 的「施工邊界」。 當然,不依賴 GitNexus,你也可以直接讓 AI 去分析整個專案,但這會非常消耗 Token。
GitNexus 在本機分析專案關聯時不耗 Token,只有後續實際調用 MCP 或是相關 Skill 時才會消耗。整體來說,這讓我省下了不少 Token,也大幅提升了邊界控制的精準度。
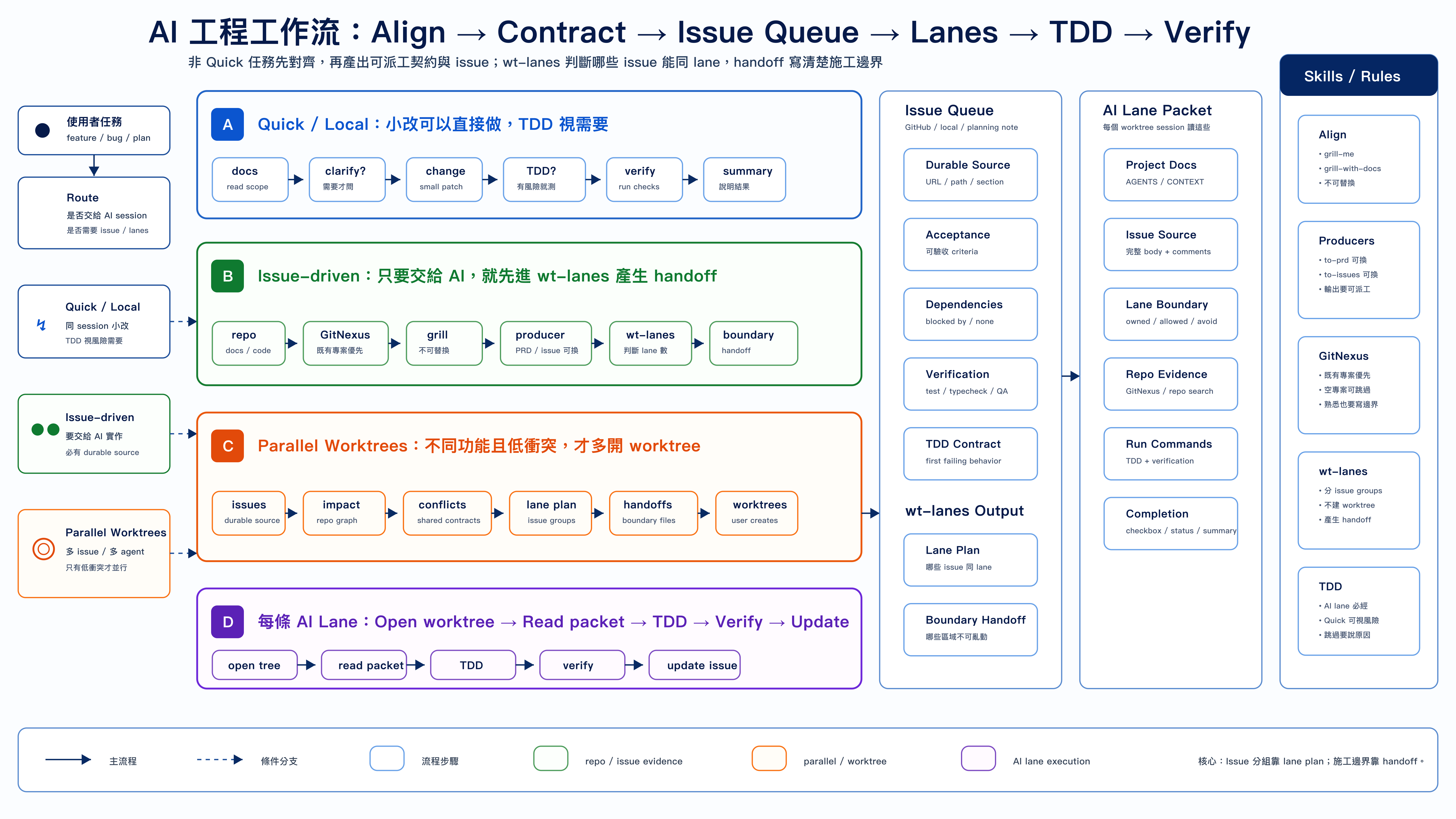
我目前的workflow
我目前的工作流大致如下圖。在接到任務(無論是修 Bug、重構或新功能)時,我會先評估任務大小,然後照著以下節奏推進:
-
對齊與拷問 (Align & Grill)
我會先使用 TypeScript 大神 Matt Pocock 寫的 grill-me-doc skill 與 AI 進行多輪對話,把需求細節釐清。Matt 的庫裡有很多實用的技能,但我還是建議,大部分的 Skill 還是要針對自己的需求客製化,效益才會最大。
-
產出藍圖 (Issue Generation & Granularity)
確認需求後,可以用 to-prd 或 to-issue 產出施工藍圖。這裡有個很大的挑戰:顆粒度的拿捏。Issue 切太小或太大都會出問題。我個人覺得 Matt 原版的 to-issue 顆粒度對我來說太小了,所以我改用自己微調的版本,並加上自己寫的 wt-lanes (Worktree Lanes) 來進行分類,把同性質的任務分在同一個區塊,方便後續開多個 Git Worktree 同步處理。
-
執行策略:慎用 Sub-agent
如果你想使用 Sub-agent(子代理)來分派任務,請務必小心。過小的任務完全沒必要開 Sub-agent。 開啟 Sub-agent 的本意是為了節省 Main-agent 的 Context Window(上下文記憶)。但 Sub-agent 是個全新的 Session,它完全依賴你傳遞給它的 Prompt。這意味著它的產出常常會偏離要求,你需要花額外的力氣去微調參數和輸入資料。很多時候,因為 Main-agent 擁有完整的歷史對話脈絡,直接讓它執行任務反而更能命中你的需求。
-
紅綠燈實作 (TDD)
切好 Worktree 後,就是嚴格執行 TDD(測試驅動開發),透過紅燈 > 綠燈的循環直到任務完成,最後再更新專案狀態。
我建議在這個流程中,留存一份文件記錄當下做的事,並且定期去優化你的流程與 Skill。
結語:從寫程式到寫架構的典範轉移
目前的體驗下來,除了非常簡單的任務外,所謂的 "Vibe Coding"(只靠出一張嘴寫 Code)能做到的其實非常有限。這背後的極限,我認為可以歸結為以下兩個核心:
-
重新認知 DDD (領域驅動設計) 的戰略價值
其實 Matt Pocock 在他的 AI 工作流中也大量融入了 DDD 的思維。這次的實戰,讓我對 DDD 有了更深一層的了解。
以前我對 DDD 的理解,多半偏向「戰術設計 (Tactical Design)」,著重在專案內如何切分 ui, app, domain, infra 來保護核心邏輯。但現在我才真正體會到,DDD 最核心的「戰略設計 (Strategic Design)」,簡直是為了約束 AI 量身打造的方法論:
- 領域知識 (Domain Knowledge): AI 不懂庫存鎖定、金流狀態等業務邏輯,這必須由工程師來定義與引導。
- 統一語言 (Ubiquitous Language): 我們產出的精確 Issue、資料結構 Schema,就是為了讓 AI 和我們使用同一種嚴謹的語言溝通,防止 AI 自行通靈。
- 限界上下文 (Bounded Context): 透過 GitNexus 控制爆炸半徑、劃定施工邊界,本質上就是把 AI 限制在特定的上下文中,不讓它去污染其他模組。
-
AI 的好球帶:Deep Modules 最近看了 TypeScript 大神 Matt Pocock 的一部影片,裡面提到了一個觀念:AI 其實更擅長處理 Deep Modules,而不是 Shallow Modules。
Deep Modules(深模組)與Shallow Modules(淺模組)這個概念,最早是來自於軟體工程界的一本書——由史丹佛大學教授 John Ousterhout 所寫的 《A Philosophy of Software Design》(軟體設計哲學)。目前我也正在拜讀中,聽說最好的吸收方式就是:看一個章節,轉頭回去檢視自己的 Code,反覆驗證這些邊界設計。接下來我也會繼續用這個節奏把它讀完:
-
Shallow Modules(淺模組): 介面複雜但內部邏輯簡單,像是到處接水管、傳遞 Props 或串接各個服務的膠水層。這類程式碼因為高度依賴整個專案的上下文,交給 AI 寫非常容易「污染」專案,引發爆炸半徑。
-
Deep Modules(深模組): 介面簡單但內部邏輯極度複雜。就像一個黑盒子,你只要定義好輸入與輸出的規格,裡面怎麼算、怎麼跑都可以。
-
總結來說: 當我們運用 DDD 的戰略思維,把系統架構拆解成一個個具備明確合約的 Deep Modules,再把這些「黑盒子」交給 AI 去跑 TDD 測試與實作,它就能在不污染專案的前提下,完美發揮它的算力。